Running Crons in Paralell – FAIL
July 16th, 2018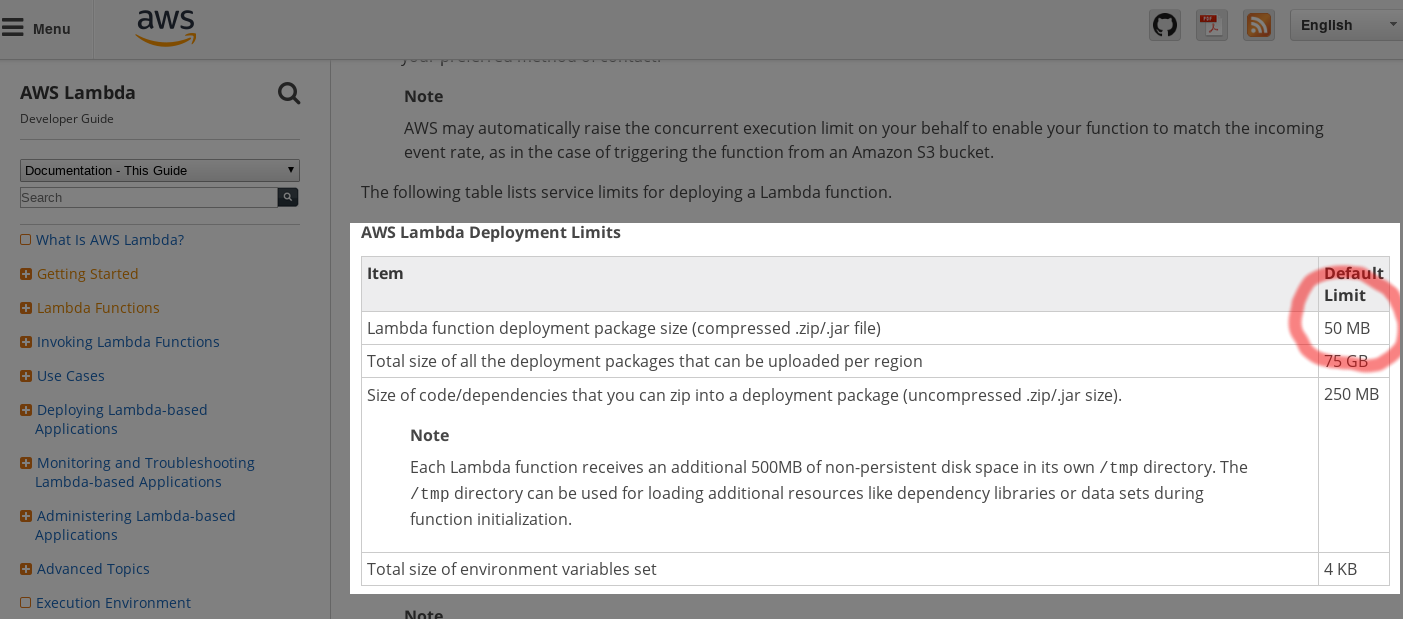
Problem:
We have dozens of clients who obtain pricing files (csv,xml,other) from distributors. Clients have an average of 2.5 distributor files. Each file has an average of 400,000 products. The process to update pricing distributor for a single client can be run via the command line :
run cron.php
Running a single pricing update is not a problem. But attempting to update all the distributors is a challenge. The main gripes are:
- It takes a very long time to run
- Memory limits crash this process
sudo apt-get install awscli
After creating the Lambda ZIP, I uploaded it to an S3 bucket and created a Lambda function called myLambdaFunction to test it out.
I want to be able to deploy many Lambda functions through the command line. So I added my ~/.aws/credentials and ~/.aws/config files and ran the following command:
$aws lambda invoke --invocation-type RequestResponse --function-name myTestLambda --log-type Tail --payload '{"key1":"value1", "key2":"value2", "key3":"value3"}' outputfile.txt
After fixing my default config timezone, I was able to run this unsuccessfully. The error I got was:
{"errorMessage":"Cannot find module '/var/task/index'","errorType":"Error","stackTrace":["Function.Module._load (module.js:417:25)","Module.require (module.js:497:17)","require (internal/module.js:20:19)"]}
Great. At least it tried to run. Now I need to fix this error. Googling the issue, it seemed to be a zip issue. I suspect that naming my file php.js is not correct, but Stack Overflow says there is corruption with the zip. I will also need to edit this and repackage it several times throughout this testing process. So I decided to create an S3FS mounting point from my instance so I can use Linux CLI to repackage the zip and move files to my bucket more easily.
It didn't work. The error says it is missing internal/module.js, which it quite likely is as I did nothing to install Node.js dependancies or anything like that.
There were a couple things wrong. I had a file named wrong and my "handler" defaulted to index when creating the function. But since my entry point was through php.js, I had to rename my handler to php.
I also had to recompile php with PDO support. After whitelisting my new EC2 Instance, I was able to execute a script which I modified to connect to the database and spit out a record. Now I just need to figure out how to grant access on my database EC2 instance from my lambda function...
As per Configuring a Lambda Function to Access Resources in an Amazon VPC I attempted to add VPC config Security Groups and Subnet Ids. It would be nicer if they gave examples, but the AWS Console Lambda VPC section is pretty good at telling you what values to put in for SecurityGroupIds and SubnetIds. That is the good news. The bad news is that it doesn't work and gives you no error message at all. So, to get past this, you need to take the values from the console and plug them into your CLI. Then you will get an error message like this:
An error occurred (InvalidParameterValueException) when calling the UpdateFunctionConfiguration operation: The provided execution role does not have permissions to call CreateNetworkInterface on EC2
I was a bit lazy with sifting through the million IAM permissions and just granted "Network Administrator Access" to my lambda_basic_executrion IAM role.
As per this AWS Forum post , you only need ec2:DescribeNetworkInterfaces, ec2:CreateNetworkInterface, and ec2:DeleteNetworkInterface. You can just turn those on if you want and go from there.
At this point, things seem optimistic. I can run some basic PHP code in a Lambda function, but I cannot get it to connect to the MySQL. My instincts tell me that this is because the database EC2 instance firewall rules do not allow Lambda to connect and thus results in a timeout. There isn't much documentation to setup VPC for your Lambda instance beyond configuring the subnets and the security group. However there is a warning:
https://aws.amazon.com/premiumsupport/knowledge-center/internet-access-lambda-function/
This project came to a halt when I was packaging PHP with some libraries, I hit the error of the archive file size being too big. Upon further research, I came across a 50MB archive size limit: https://docs.aws.amazon.com/lambda/latest/dg/limits.html
A stripped down Docker image of PHP is about 30MB. Our code base is over 300 MB uncompressed and when compressed it would be well over the remaining 20MB allocated for the archive. I won't revisit this problem unless Lambda processes begin to support PHP.
FAIL.
Interim Solution
PHP was running a script that used a huge chunk of memory and had a memory leak. I did my best to find the memory leak but I couldn't. There were many dependencies upon which this code ran and I feel it was one of these dependencies that were leaking. When a function returns, I expect the memory from that function to be freeable. In this situation, it wasn't. So as the cron ran, it grew. We could have potentially thrown 16 or 32 GB of ram at this problem (and still might), but I felt if only I could free the RAM from function to function, it would be fine. So I continued on with a wrapper that I was going to build. If you recall, I was going to send each distributor/dealer to a separate Lambda function to run. In order to do that, I had to put the logic of which dealer and supplier I have to run and send each to a Lambda function. This logic currently existed in PHP, so I moved this logic to BASH. To be clear, this fixes my RAM problem because instead of PHP managing memory, BASH does. And with the way I do it by running a bash script to completion, it will free up the memory when the process dies. It then sleeps for up to a minute when the next cron is run. I want this code to work on multiple instances without conflict so I really needed a job pool manager. Currently, we have a query that pulls the distributors and dealers that haven't successfully run. But knowing whether or not the process has run, doesn't work because when I am picking a job from the pool, I have to ignore all those that are running. So I created a start_log table that allows me to use the existing query, but ignore anything that has started running within the last 7 days. With that modified query, I can further modify it by adding an optional "limit" variable. So that I only select 1 distributor/dealer to run. Then I run it and log that I have started running it before I PDO::beginTransaction. I also added a checker on each server which looks at the process list psps xa | grep distributors
which I then probe results for. The is a very low load function which I feel confident can run every minute to determine if the system is currently actively running the distributors cron. Here is some pseudo code for the solution:
if (!cronIsRunning()){
run cron.php limit=1
}
Limit ensures I check the job pool and return a single result. I then log the start of the job and do as before. I am still playing around with PDO transactions. I find it can seize the DB for some seconds, but makes the cron run so much faster. So I prefer to run this cron with PDO enabled during off-peak hours.
As it stands now, we use 3GB for the PHP memory limit. The largest amount of memory used by a single cron, dealer last week was 3GB (It was starting at 2800MB and running out). Now the highest memory limit is 1211 MB. The longest script to run took 16 minutes.
In conclusion, when I inherited this code it was maxing out on a server with only 1GB of ram. Upon upgrading to 4 GB of ram and letting it run on 3, it would run out of RAM and some processes would take for hours. It would fail at some point and I would run a cron later to restart the original from where it left off. But when PHP manages the memory, somebody's code is leaking memory. Some distributor crons were taking hours to run. So I modified the code to begin and post transactions to limit the actual database connections from 500,000+ writes to 1. This helped the distributor import run in a reasonable amount of time but didn't fix the RAM leak. Changing this over to a BASH script which runs the PHP script with strictly 1 distributor/dealer that can run within 3GB of ram. When this process ends, so does the BASH process and therefore all the RAM they consumed.
We can still scale this process by creating multiple instances of this. When things run for minutes, when given enough instances, you will eventually get an occasional conflict where they try to write to the database at the same time and one has to wait for another. And unfortunately, you can't use Lambdas to make these all run at the exact same time. Boo! But, we can scale this with several instances, run them more frequently (we used to run them only Sunday nights). This should be a viable solution for the medium term.
Posted In:
ABOUT THE AUTHOR:Software Developer always striving to be better. Learn from others' mistakes, learn by doing, fail fast, maximize productivity, and really think hard about good defaults. Computer developers have the power to add an entire infinite dimension with a single Int (or maybe BigInt). The least we can do with that power is be creative.

 The Limiting Factor
The Limiting Factor Whole Mars Catalog
Whole Mars Catalog